[논문리뷰] Respecting Transfer Gap in Knowledge Distillation
요약
- Class가 Balanced 하더라도 Context가 imbalance 할 수 있다. 따라서 Context를 KL로 Teacher 모델과 똑같이 학습하는 것은 너무 강력한 제약사항이다.
- KD를 하는 과정에서 Context 정보를 class cross-entropy loss와 비율로써 반영 가능 하도록 IPW를 활용한다.
1. Motivation
- Imbalanced Teacher knowledge을 Student에게 전달 하면 큰 학습 효과를 보기 어렵다.
- Class가 balanced하더라도 Context가 imbalanced 할 수 있기 때문에 이를 보정작업 없이 knowledge distillation을 시도하면 Student가 정보를 왜곡하여 학습 할 수 있다.
- 또한, 이러한 Non-IID 데이터에서 Knowledge distillation을 수행하는 것에 있어 KL을 사용하면 너무 정확하게 정보를 학습하여 효과적이지 않다.
- 따라서 본 논문에서는 Inverse Probability Weighting(IPW)를 활용하여 Teacher와 Student의 transfer gap을 메꾸는 방법을 소개한다.
2. Method
우선 Knowledge를 Distill 하기위해 Student network 구조를 변경한다. Class를 예측하는 CLS head와 KD를 수행하는 KD head를 두어 서로 다른 logit을 생성하게 유도한다.
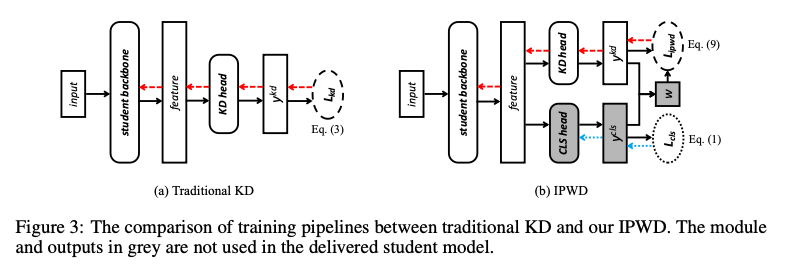
이때 IPW를 활용하여 KD 수행시 가중치(weight)를 반영하여 context에서 실제 class와의 관계 정보를 학습 시 고려하게 한다. Traditional IPW estimatesms logistic regression을 사용하여 경향(propensity) score를 측정하는데, KD head 쪽에서의 logit에는 representation 분포에 대한 정답 label이 없기 때문에 이를 unsupervised 방법으로 추정한다.
추정하고자 하는 $\hat{w}_x$는 class cross-entropy와 kd cross-entropy의 비율로 추정한다.
$$\hat{w}_x=1+\frac{H(y^{kd}, y)}{H(y^{cls},y)}$$
$\hat{w}_x$는 $y^{cls}$와 $y^{kd}$의 confident에 따라 결정된다. $y^{cls}$의 cross-entropy가 더 낮다면($y^{cls}$ confident가 더 높다) 큰 가중치가 할당되어 $y^{kd}$를 더 학습하게 유도하고, 반대로 $y^{kd}$의 cross-entropy가 더 낮다면($y^{kd}$의 confident가 더 높다면) 작은 가중치를 할당하여 $y^{cls}$를 더 학습하도록 유도한다. 즉, representation을 적게 학습하는 경우에 가중치를 통해 representation을 더 학습하도록 유도하는 것이다.

Weighted distillation loss는 아래와 같이 정의한다.
$$\mathcal{L}_{ipw-dist}=\frac{1}{|\mathcal{D}^t|}\sum_{(x,y^t)\in\mathcal{D}^t}\hat{w}_x \cdot \ell_{dist}(x, y^t;\theta)$$
최종적인 IPWD loss 함수는 아래와 같다.
$$\mathcal{L}_{ipwd}=\mathcal{L}_{cls}+\alpha\mathcal{L}_{ipw-dist}$$
3. Evaluation
그럼에도 불구하고 Accuracy가 크게 증가하진 않았다. 물론 모든 케이스에서 SOTA 성능을 보이긴 했지만, 1~2%정도 향상 효과를 나타낸다.

4. 시사점
- 본 논문은 Knowledge Distillation에 있어서 Non-IID 상황을 고려했다는 것을 주목할만하다.
- Context의 logit과 class logit을 비교하여 representiation이 잘 학습되지 않는 경우, loss에 대한 가중치를 더 부여하여 representation을 더 많이 학습하도록 유도한다.
- 반대로 class에 대한 예측을 잘 수행하지 못하는 경우, 즉 Teacher의 knowledge가 오히려 학습을 방해 할 때는 Distillation의 비율을 작게하여 class에 대한 학습을 더 하도록 유도한다.
- 결국 이 논문도 feature representation이 하나의 클래스에 오버피팅되는 경우를 예방하는 것이 목표다.